

Hardware-Heavy Product Development: Tech Selection Guide

Introduction
Even the most experienced design engineers have moments of doubt when staring at a project schedule and countless datasheets, wondering, "How do I know I'm choose the right technology?"
While selecting technology based solely on specifications seems systematic, how can you truly ensure the platform you build your solution on will deliver long-term success for your finished product and prove its value to stakeholders?
The early decisions you make on underlying technology platforms and system architecture can determine whether you achieve your objectives. Certain goals may be clear from the beginning, such as functional performance metrics and launch schedule, while others, such as user-requested features and the long-term technical maintenance burden, may be unknown at project kickoff, but no less impactful. So why not approach these critical decisions with a proven framework that transforms uncertainty into confidence and mitigates risk, even for some of the unknowns?
Engineering teams today face an overwhelming array of processing architectures, form factors, and software stack design decisions, all while navigating the core trade-offs between system performance, budget, and development speed.
Without the right criteria for choosing a technology stack to build their solution on, many fail to attain their market objectives. For example, many face the common pitfall of prematurely optimizing unit costs, which can significantly delay launch schedule, market uptake, and time-to-profit. Nothing is more expensive than failing to get to market at all.
Below are a few examples of applications with high-complexity requirements where platform selection is non-trivial.
Infrastructure monitoring systems (extreme environments, long lifecycle, remote deployment, total cost of ownership)
High-speed automation processes (microsecond-level determinism, real-time performance, industrial networks)
Healthcare edge devices (compliance requirements, security architecture)
Equipment protection systems (fail-safe operation, environmental hardening)
Industrial IoT AI inference systems (edge processing, model lifecycle management)
This comprehensive white paper series aims to provide engineering teams with a structured methodology for evaluating product development platforms across a wide range of application spaces. We'll guide you beyond surface-level specifications to the considerations and factors that determine success from initial research through long-term product sustainment.

Our selection framework for high complexity, medium volume product deployments addresses eight critical evaluation dimensions that separate successful deployments from costly mistakes:
Signal Integration & I/O Mix
Processing & Compute
Software Toolchain
Deployment Environment
Cost Models
Security Architecture
AI Integration
Voltage is the difference of electrical potential between two points of an electrical or electronic circuit, expressed in volts. It measures the potential energy of an electric field to cause an electric current in an electrical conductor.
To measure voltage, two considerations need to be. 1) The voltage level at which the measurement is referenced to, as well as 2) the signal source. The two methods to measure voltage are ground reference and differential. Common signal source types are floating signal sources and grounded signal sources.
Both signal sources have optimal connection diagrams based on the individual measurement method. Please note that depending on the type of signal, a particular voltage measurement method may provide better results than others. Learn more about Field Wiring and Noise Considerations for Analog Signals.

Measurement Reference Point Methods
There are two methods to measure voltages: ground referenced and differential.
Ground-Referenced Voltage Measurement (RSE or NRSE)
One voltage measurement method is to measure voltage with respect to a common, or a “ground,” point. Usually, these “grounds” are stable and around 0 V. Historically, the term ground originated from ensuring the voltage potential is at 0 V by connecting the signal to the earth. Ground-referenced input connections are good for a channel that meets the following conditions:
-
Input signal is high-level (greater than 1 V)
-
Leads connecting the device's signal are less than 10 ft
-
The input signal can share a common reference point with other signals
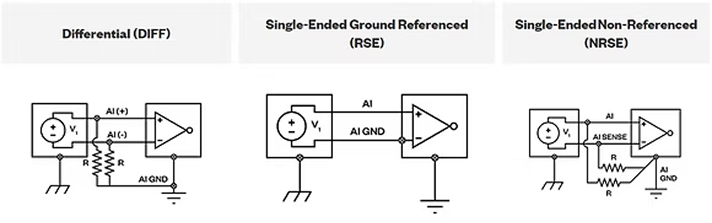
The ground reference is provided by either the device taking the measurement or by the external signal being measured. When the ground is provided by the device, this setup is called ground-referenced single-ended mode (RSE), and when the ground is provided by the signal, the setup is called nonreferenced single-ended mode (NRSE).
Differential Voltage Measurement (DIFF)
Another way to measure voltage is to determine the “differential” voltage between two separate points in an electrical circuit. For example, to measure the voltage across a single resistor, you measure the voltage at both ends of the resistor. The difference between the voltages is the voltage across the resistor. Usually, you can use differential voltage measurements to determine the voltage that exists across individual elements of a circuit—or you can use this method when the signal sources are noisy.
Differential input connections are particularly well suited for a channel that meets any of the following conditions:
-
The input signal is low-level (less than 1 V)
-
The leads connecting the signal to the device are greater than 3 m (10 ft)
-
The input signal requires a separate ground reference point or return signal
-
The signal leads travel through noisy environments
In differential mode, the negative signal is wired to and analog pin directly facing the analog channel that is connected to the positive signal. The disadvantage of differential mode is that it effectively reduces the number of analog input measurement channels by half.
Types of Signal Sources
Before configuring the input channels and making signal connections, you must determine whether the signal sources are floating or ground referenced.
Floating Signal Sources
A floating signal source is not connected to the building ground system but has an isolated ground reference point. Some examples of floating signal sources are outputs of transformers, thermocouples, battery-powered devices, optical isolators, and isolation amplifiers. An instrument or device that has an isolated output is a floating signal source. The ground reference of a floating signal must be connected to the ground of the device to establish a local or onboard reference for the signal. Otherwise, the measured input signal varies as the source floats outside the common-mode input range.
For floating signals, you have several options when it comes to input configurations: differential (DIFF), single-ended ground referenced (RSE), or single-ended non-referenced (NRSE).
Ground-Referenced Signal Sources
A ground-referenced signal source is connected to the building system ground, so it is already connected to a common ground point with respect to the device, assuming that the measurement device is plugged into the same power system as the source. Non-isolated outputs of instruments and devices that plug into the building power system fall into this category. The difference in ground potential between two instruments connected to the same building power system is typically between 1 and 100 mV, but the difference can be much higher if power distribution circuits are improperly connected. If a grounded signal source is incorrectly measured, this difference can appear as measurement error. Following the connection instructions for grounded signal sources can eliminate the ground potential difference from the measured signal.
For grounded signals, you have two options when it comes to input configurations, differential (DIFF) or single-ended non-referenced (NRSE). NI does not recommend that you use single-ended ground referenced input configurations for grounded signal sources.

Grounded Signal Source Input Configuration
For grounded signals, you have two options when it comes to input configurations. Note: NI does not recommend that you use single-ended ground referenced input configurations for grounded signal sources.
Voltage Measurement Considerations
When measuring voltage, you should consider things such as high-voltage measurement, ground loops, common-mode voltage, and isolation topologies.
High-Voltage Measurements and Isolation
There are many issues to consider when measuring higher voltages. When specifying a data acquisition system, the first question you should ask is whether the system will be safe. Making high-voltage measurements can be hazardous to your equipment, to the unit under test, and even to you and your colleagues. To ensure that your system is safe, you should provide an insulation barrier between the user and hazardous voltages with isolated measurement devices.
Isolation, a means of physically and electrically separating two parts of a measurement device, can be categorized into electrical and safety isolation. Electrical isolation pertains to eliminating ground paths between two electrical systems. By providing electrical isolation, you can break ground loops, increase the common-mode range of the data acquisition system, and level shift the signal ground reference to a single system ground. Safety isolation references standards that have specific requirements for isolating humans from contact with hazardous voltages. It also characterizes the ability of an electrical system to prevent high-voltage and transient voltages to be transmitted across its boundary to other electrical systems with which the user may come in contact.
Incorporating isolation into a data acquisition system has three primary functions: preventing ground loops, rejecting common-mode voltage, and providing safety.
Learn more about high-voltage measurements and isolation.
Ground Loops
Ground loops are the most common source of noise in data acquisition applications. They occur when two connected terminals in a circuit are at different ground potentials, causing current to flow between the two points. The local ground of your system can be several volts above or below the ground of the nearest building, and nearby lightning strikes can cause the difference to rise to several hundreds or thousands of volts. This additional voltage itself can cause significant error in the measurement, but the current that causes it can couple voltages in nearby wires as well. These errors can appear as transients or periodic signals. For example, if a ground loop is formed with 60 Hz AC power lines, the unwanted AC signal appears as a periodic voltage error in the measurement.
When a ground loop exists, the measured voltage, ΔVm, is the sum of the signal voltage, Vs, and the potential difference, ΔVg, which exists between the signal source ground and the measurement system ground, as shown in Figure 6. This potential is generally not a DC level; thus, the result is a noisy measurement system often showing the 60 Hz power-line frequency components in the readings.

To avoid ground loops, ensure that there is only one ground reference in the measurement system, or use isolated measurement hardware. Using isolated hardware eliminates the path between the ground of the signal source and the measurement device, thus preventing any current from flowing between multiple ground points.
Common-Mode Voltage
An ideal differential measurement system responds only to the potential difference between its two terminals, the (+) and (-) inputs. The differential voltage across the circuit pair is the desired signal, yet an unwanted signal may exist that is common to both sides of a differential circuit pair. This voltage is known as common-mode voltage. An ideal differential measurement system completely rejects, rather than measures, the common-mode voltage. Practical devices, however, have several limitations, described by parameters such as common-mode voltage range and common-mode rejection ratio (CMRR), which limit this ability to reject the common-mode voltage.
The common-mode voltage range is defined as the maximum allowable voltage swing on each input with respect to the measurement system ground. Violating this constraint results not only in measurement error but also in possible damage to components on the device.
Common-mode rejection ratio describes the ability of a measurement system to reject common-mode voltages. Amplifiers with higher common-mode rejection ratios are more effective at rejecting common-mode voltages.
In a non-isolated differential measurement system, an electrical path still exists in the circuit between input and output. Therefore, the electrical characteristics of the amplifier limit the common-mode signal level that you can apply to the input. With the use of isolation amplifiers, the conductive electrical path is eliminated, and the common-mode rejection ratio is dramatically increased.
Isolation Topologies
It is important to understand the isolation topology of a device when configuring a measurement system. Different topologies have several associated cost and speed considerations. Two common topologies are channel-to-channel and bank.
Channel-to-Channel
The most robust isolation topology is channel-to-channel isolation. In this topology, each channel is individually isolated from one another and from other non-isolated system components. In addition, each channel has its own isolated power supply.
In terms of speed, there are several architectures from which to choose. Using an isolation amplifier with an analog-to-digital converter (ADC) per channel is typically faster because you can access all the channels in parallel. A more cost-effective yet slower architecture involves multiplexing each isolated input channel into a single ADC.
Another method of providing channel-to-channel isolation is to use a common isolated power supply for all the channels. In this case, the common-mode range of the amplifiers is limited to the supply rails of that power supply, unless you use front-end attenuators.
Bank
Another isolation topology involves banking, or grouping, several channels together to share a single isolation amplifier. In this topology, the common-mode voltage difference between channels is limited, but the common-mode voltage between the bank of channels and the non-isolated part of the measurement system can be large. Individual channels are not isolated, but banks of channels are isolated from other banks and from ground. This topology is a lower-cost isolation solution because this design shares a single isolation amplifier and power supply.
Measure Voltage with NI Hardware
The acquisition hardware’s quality determines the quality of the voltage data you collect. NI offers a range of that can accurately measure voltage over a wide range of values and generate voltage signals for control and communication applications. NI voltage products have options that are optimized for industrial or hazardous locations and can have built-in isolation and overcurrent protection for high-voltage applications.

Build your system. We're here to help.
Precision automation for test, control, and performance-critical applications.




